Exploring data I
Lecture 4
September 10, 2024
Histogram - Step 1

Histogram - Step 2
Histogram - Step 3
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.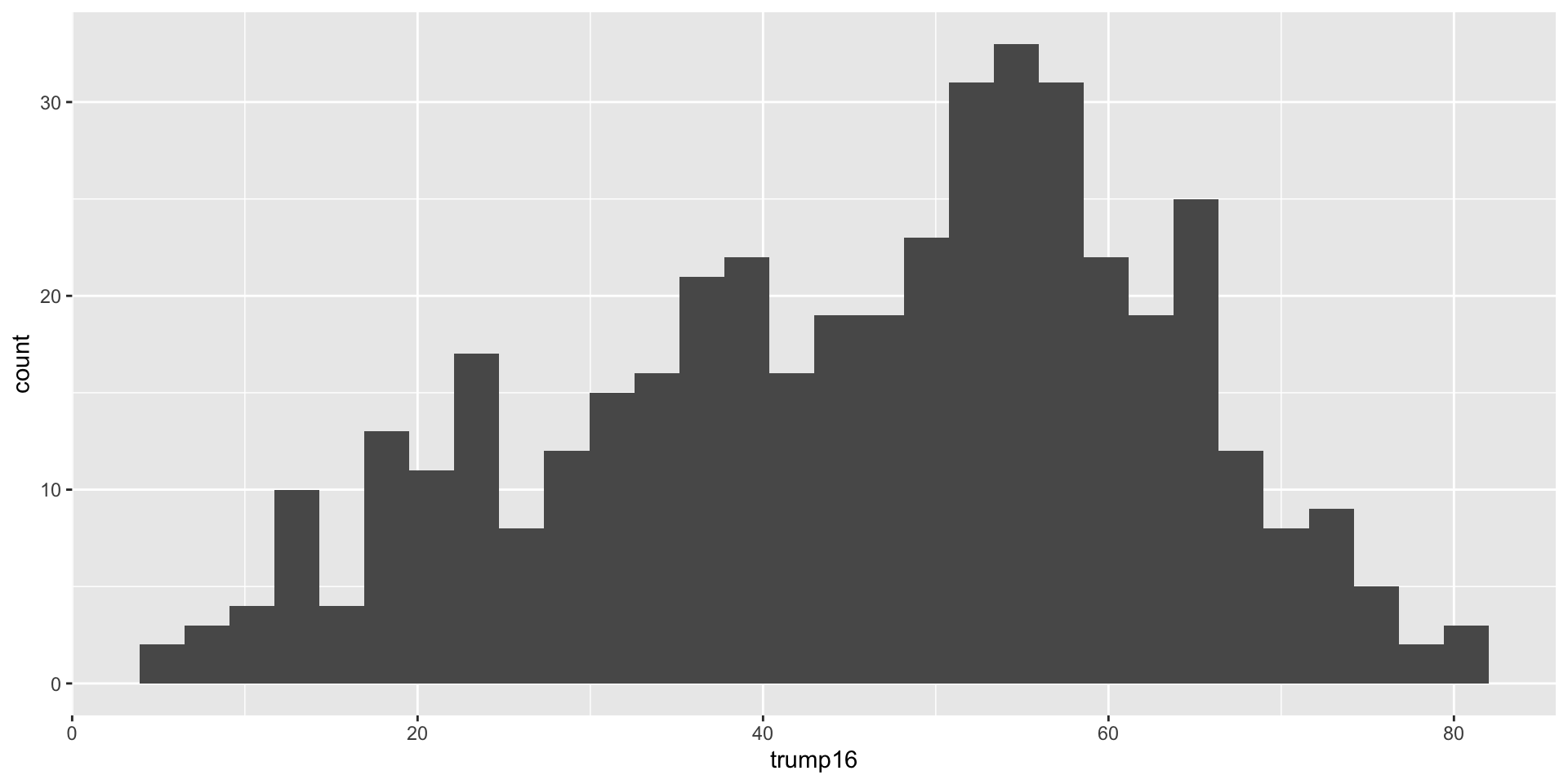
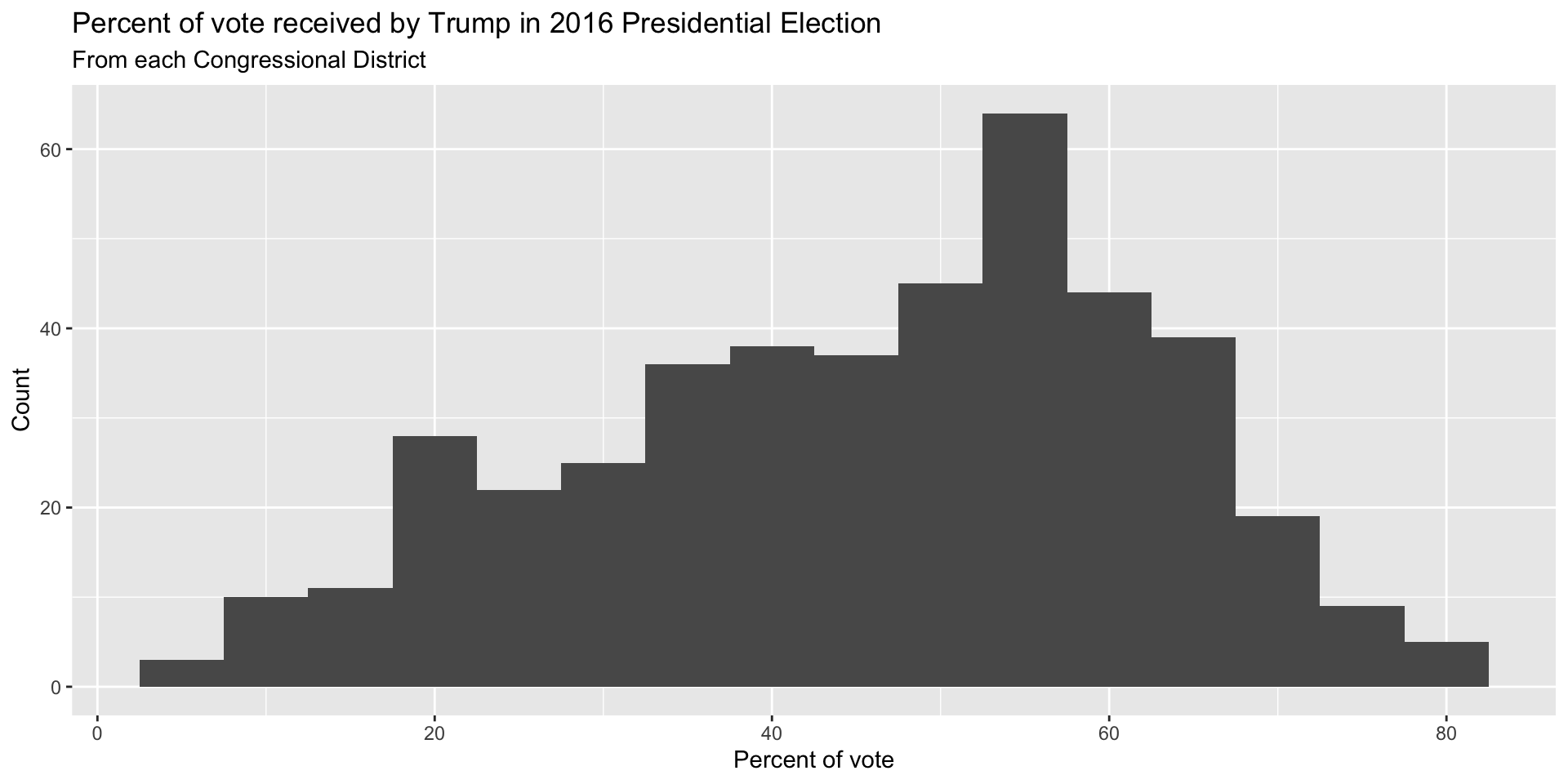
Histogram - Step 5
Box plot - Step 1

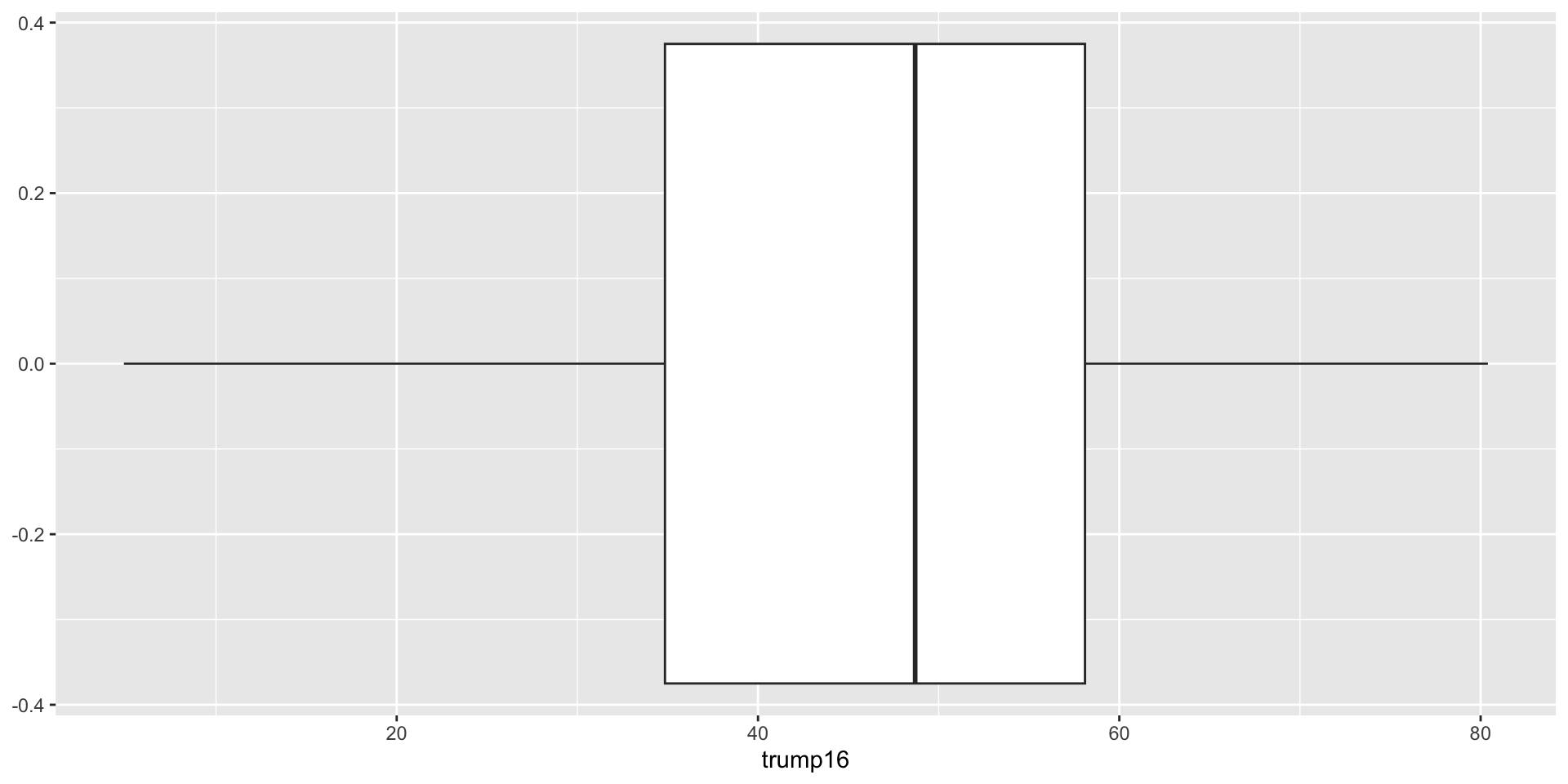
Box plot - Step 2
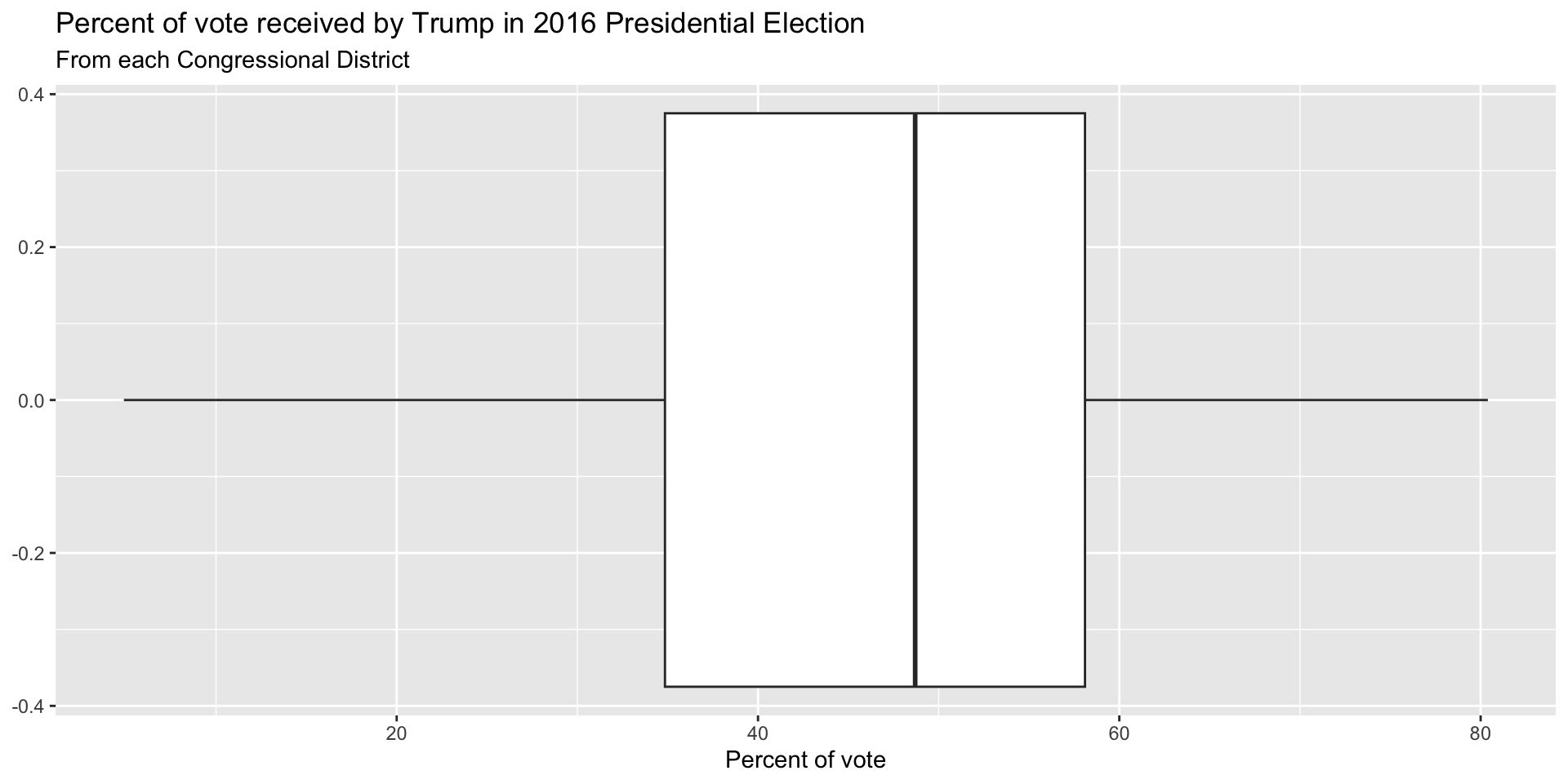
Box plot - Step 3
Box plot - Step 4
Density plot - Step 1

Density plot - Step 2
Density plot - Step 3
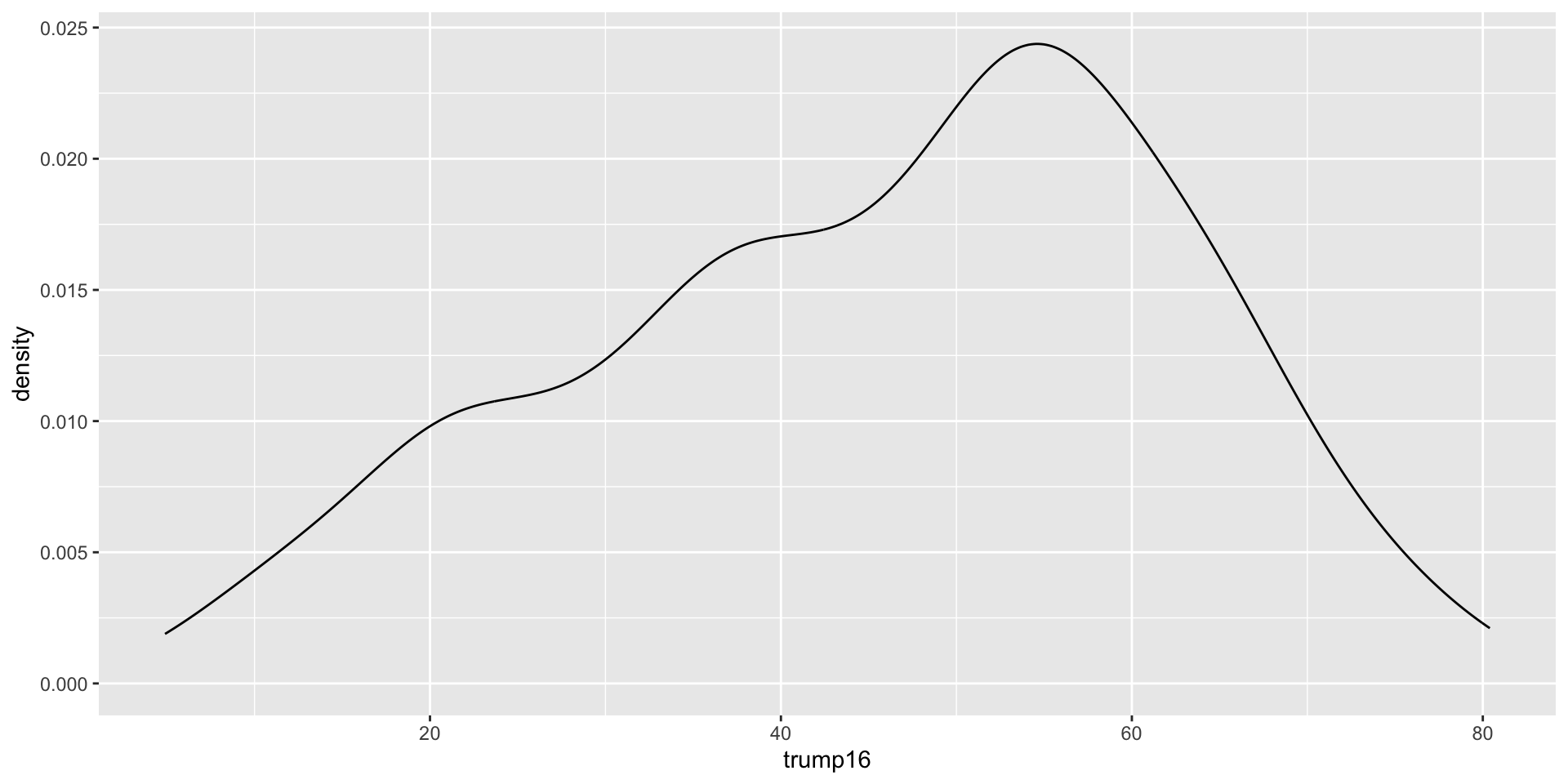
Density plot - Step 8
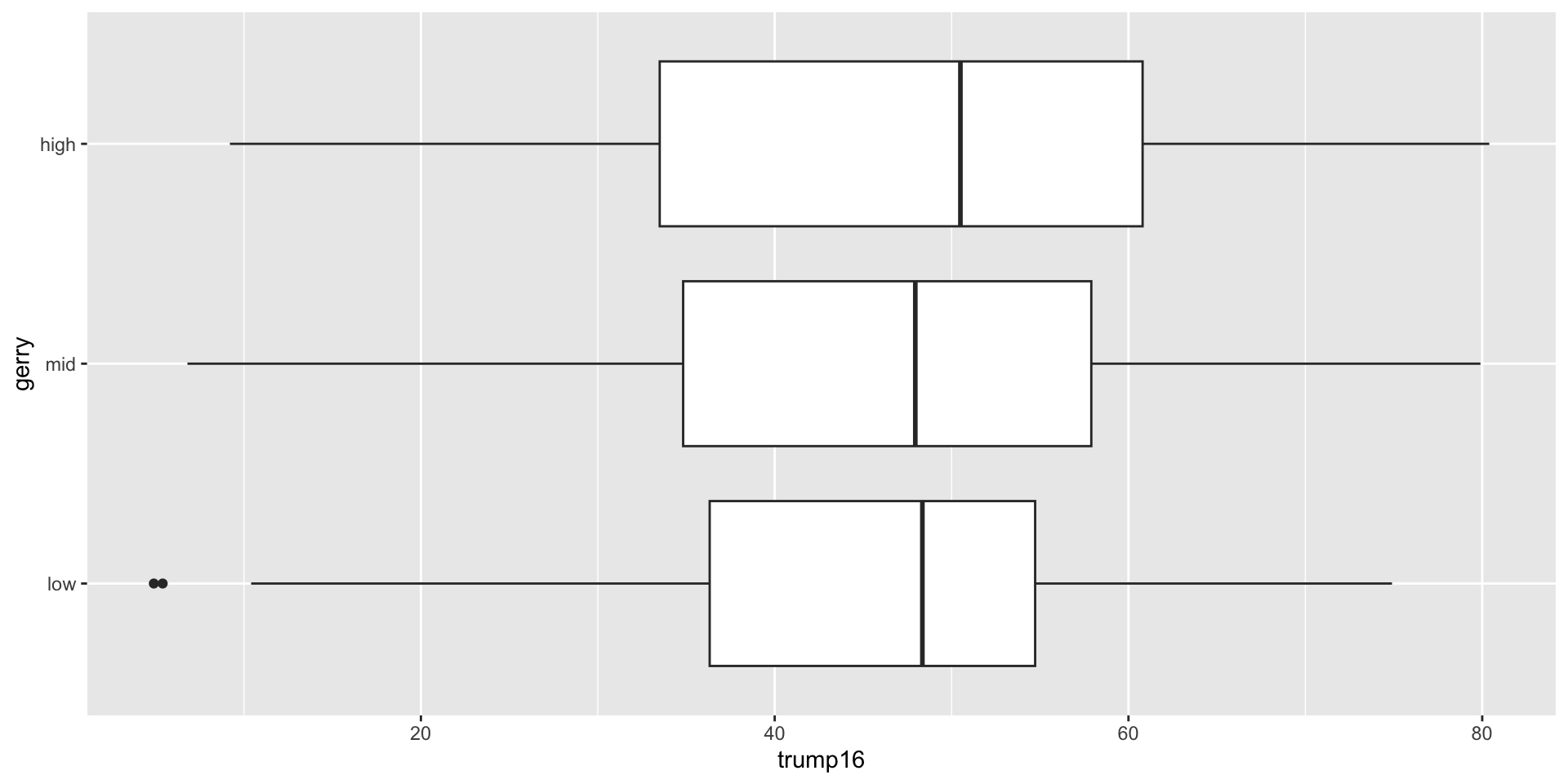
Side-by-side box plots
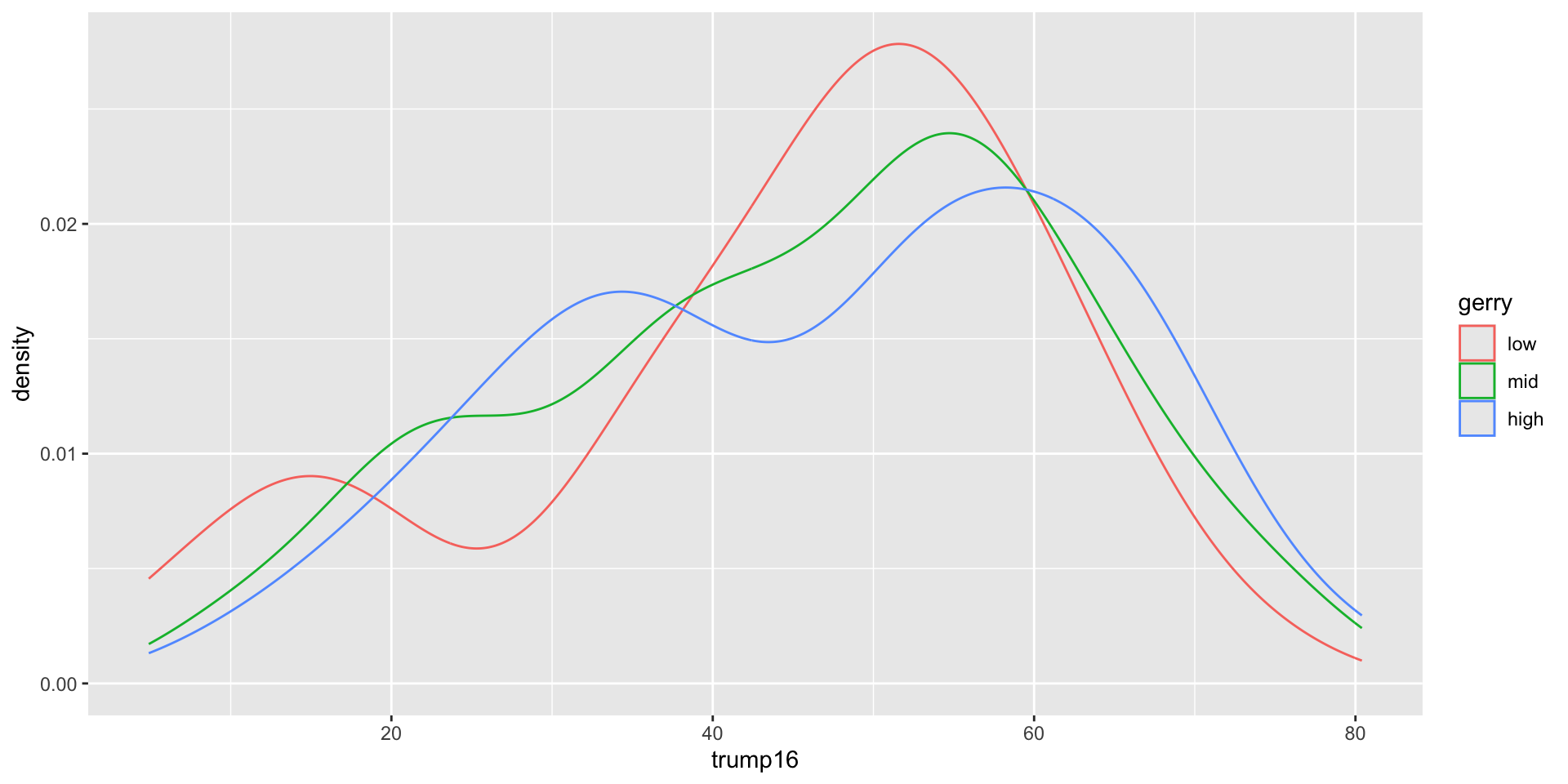
Density plots
Filled density plots
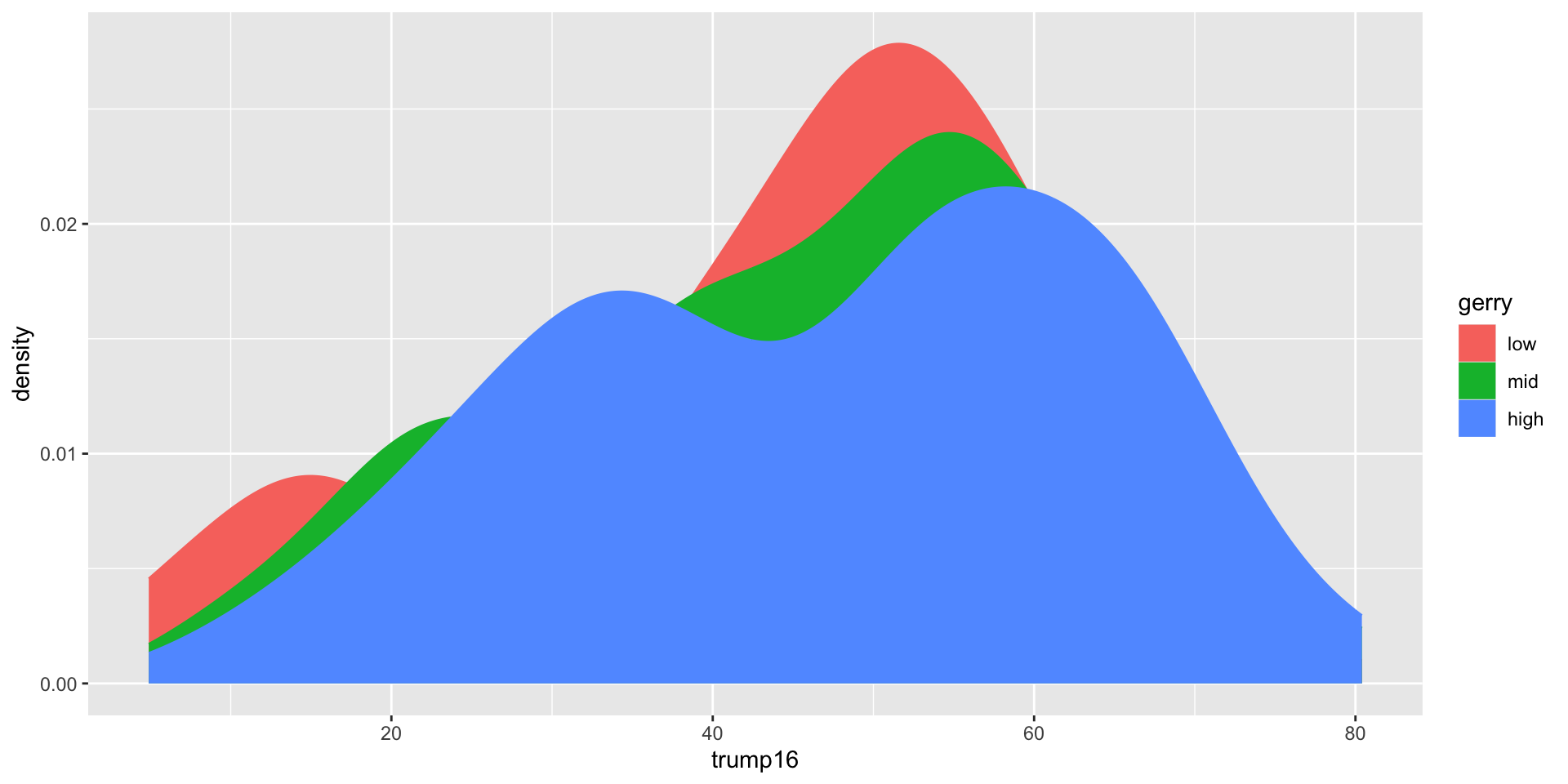
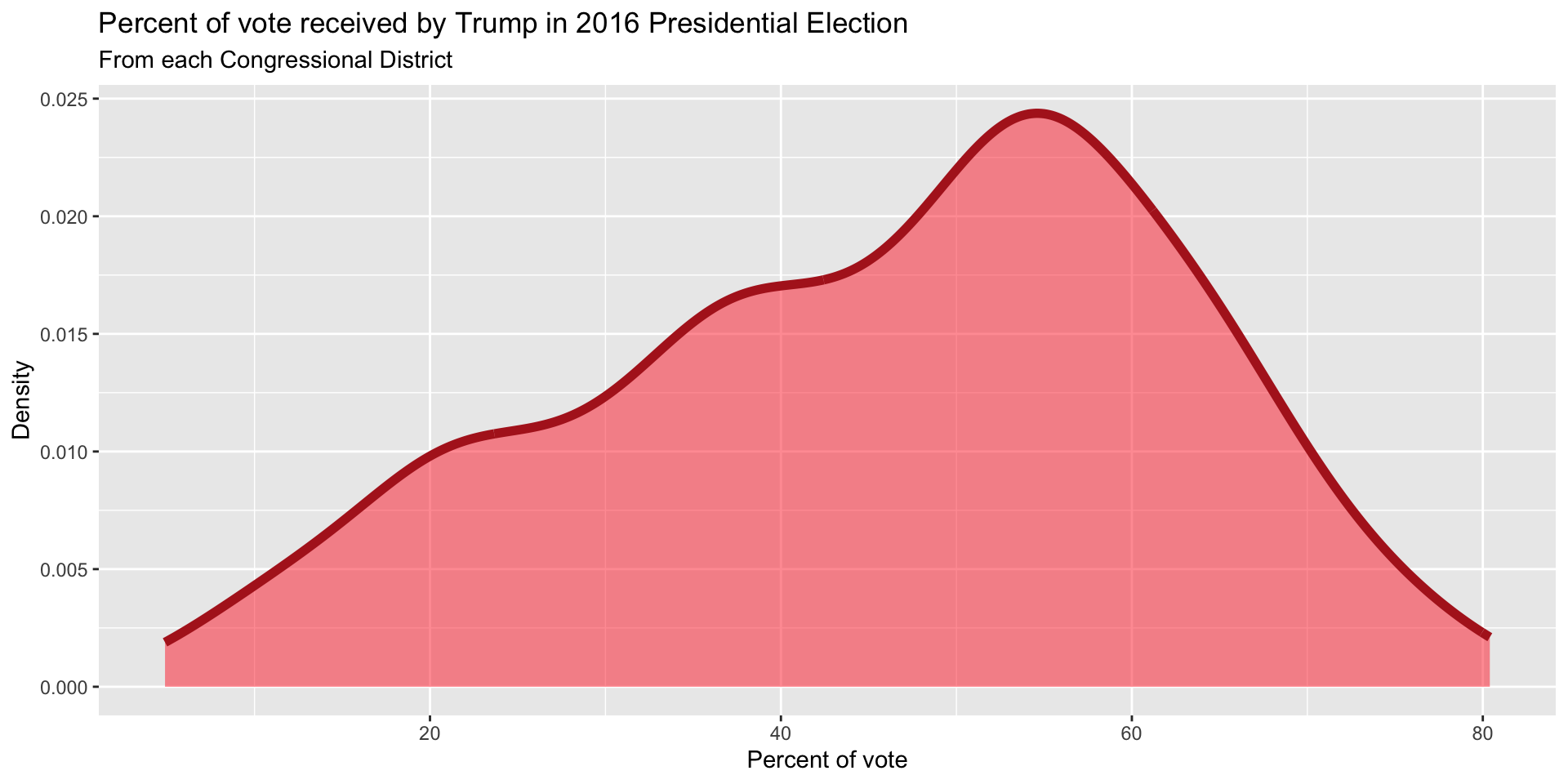
Better filled density plots
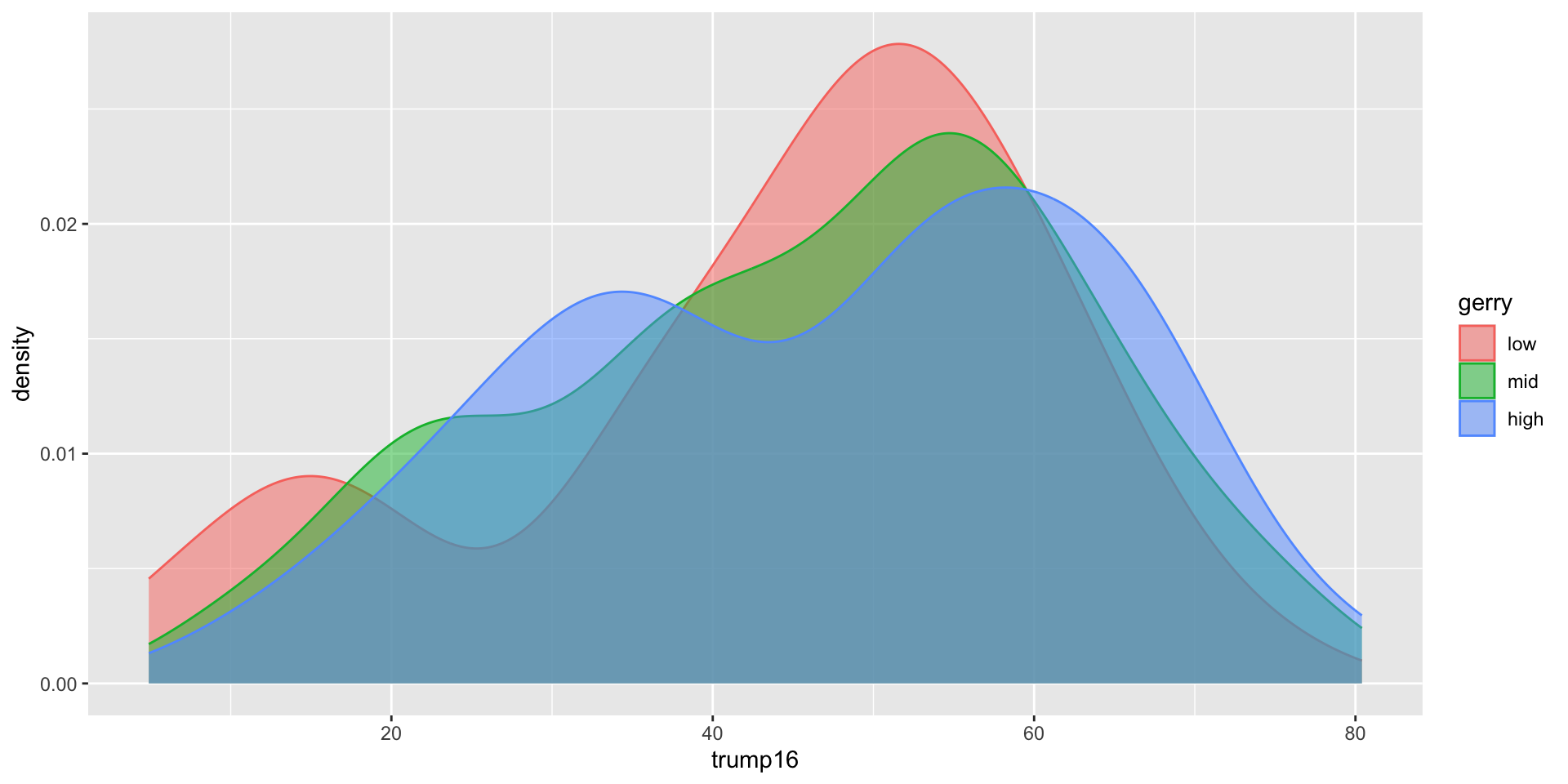
Better colors
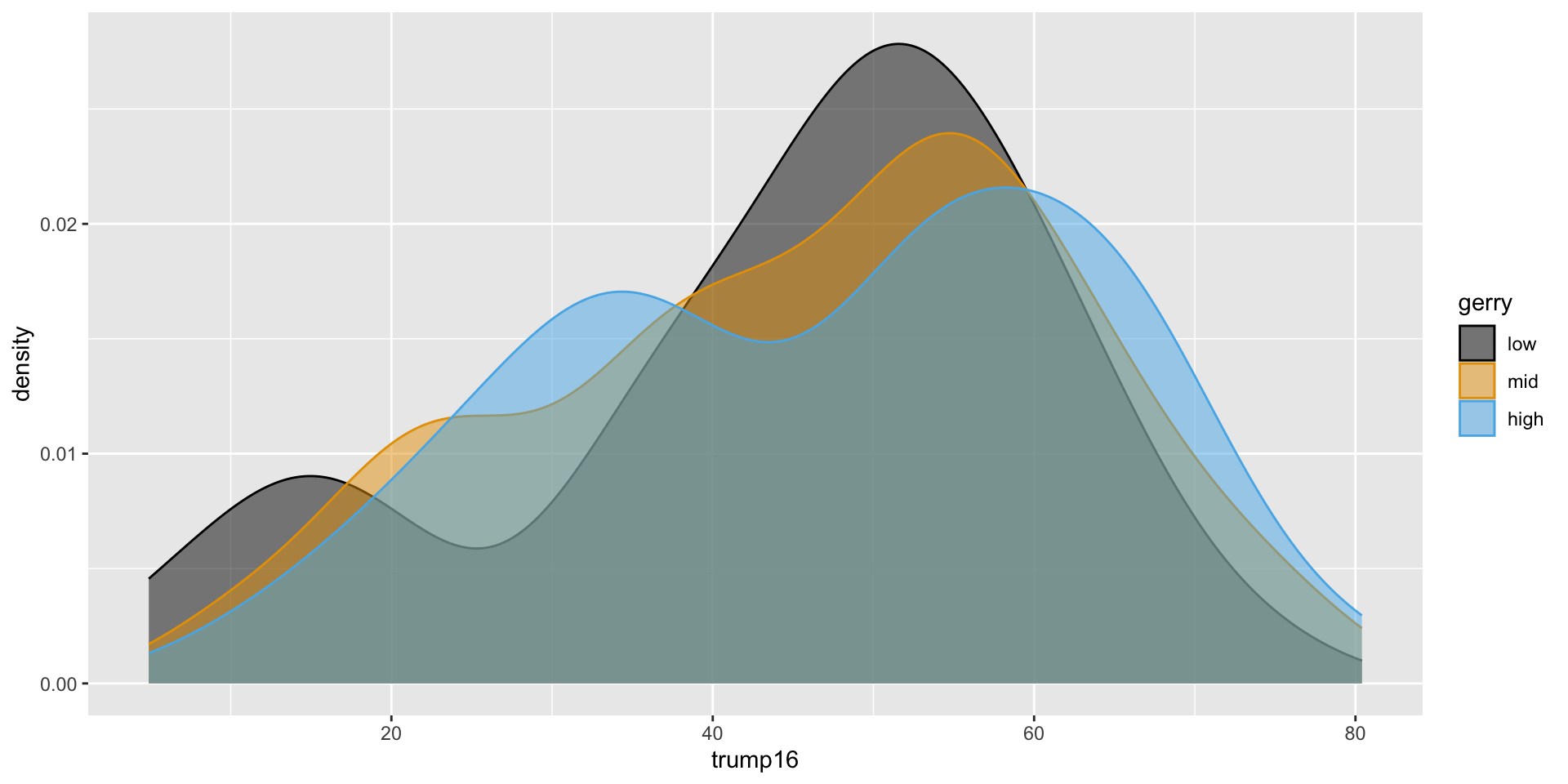
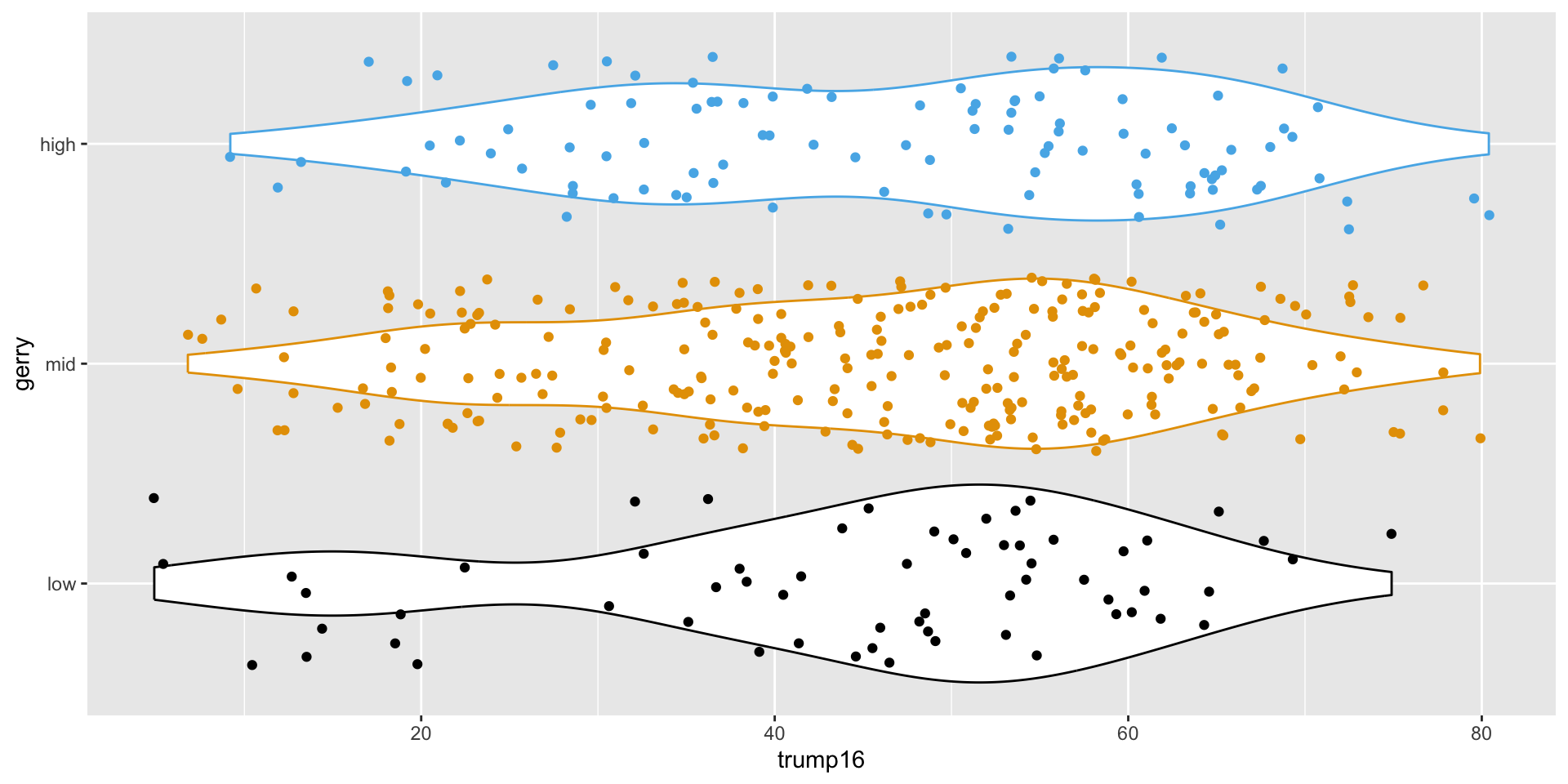
Violin plots
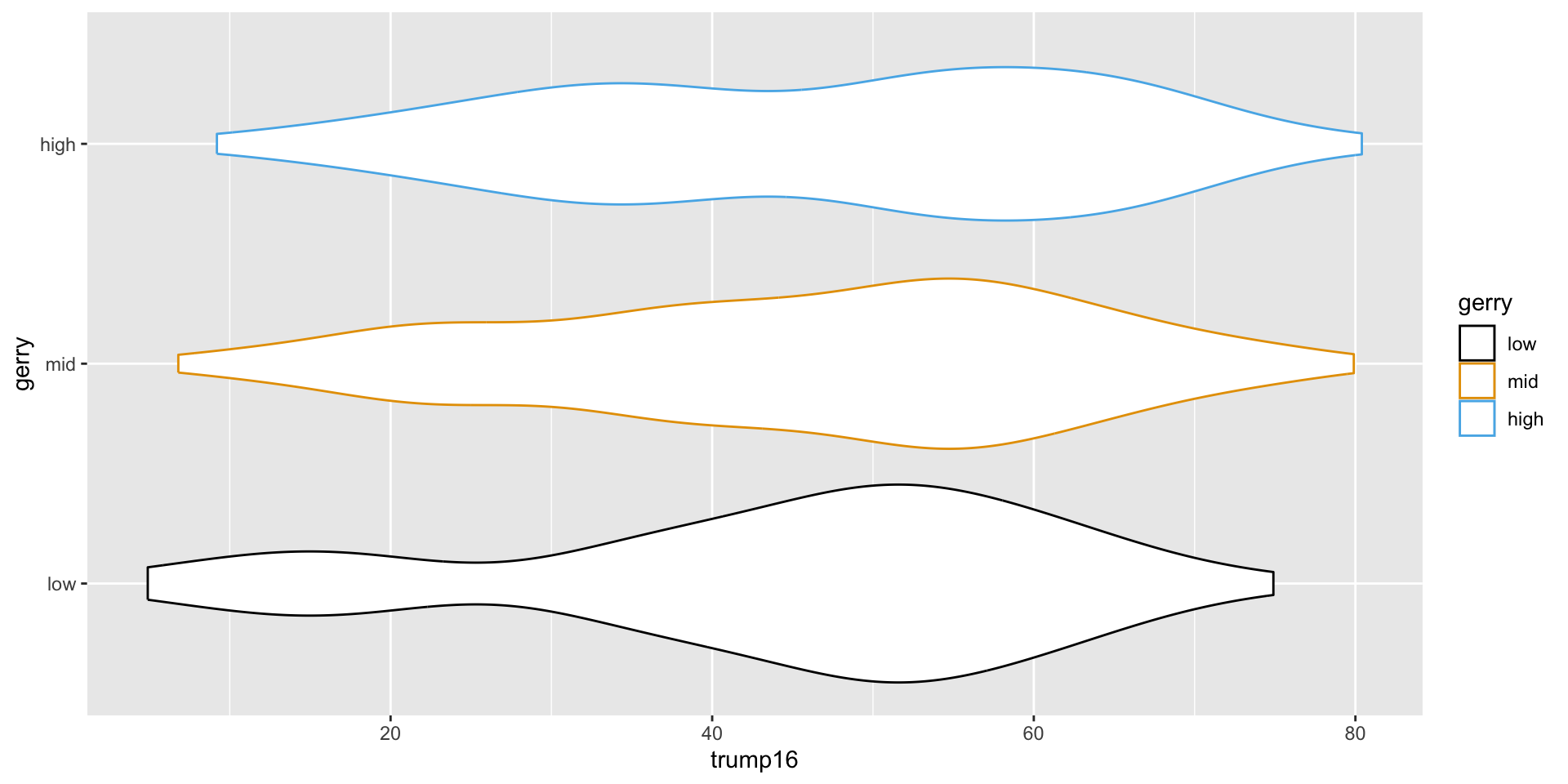
Multiple geoms
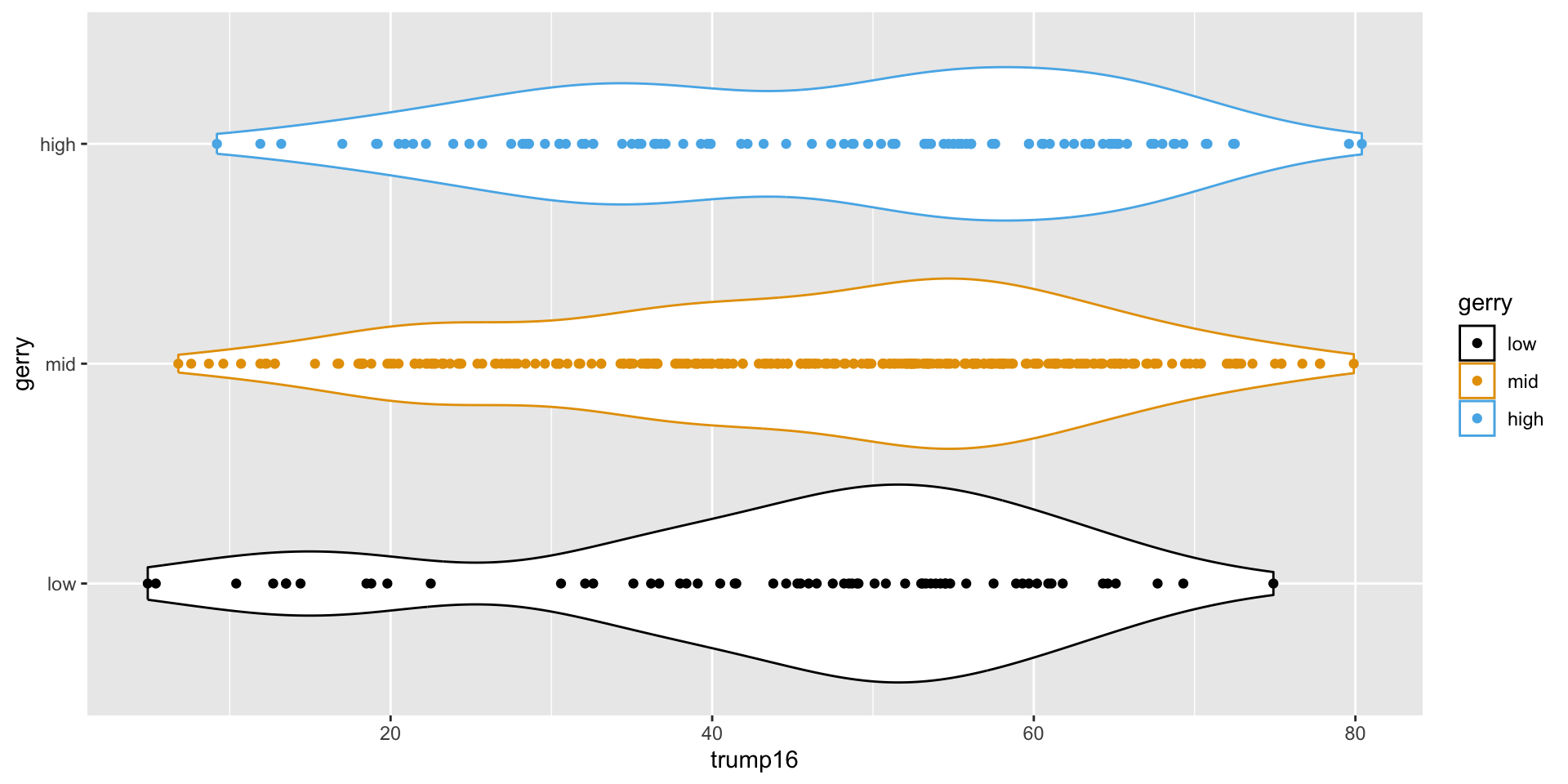
Multiple geoms
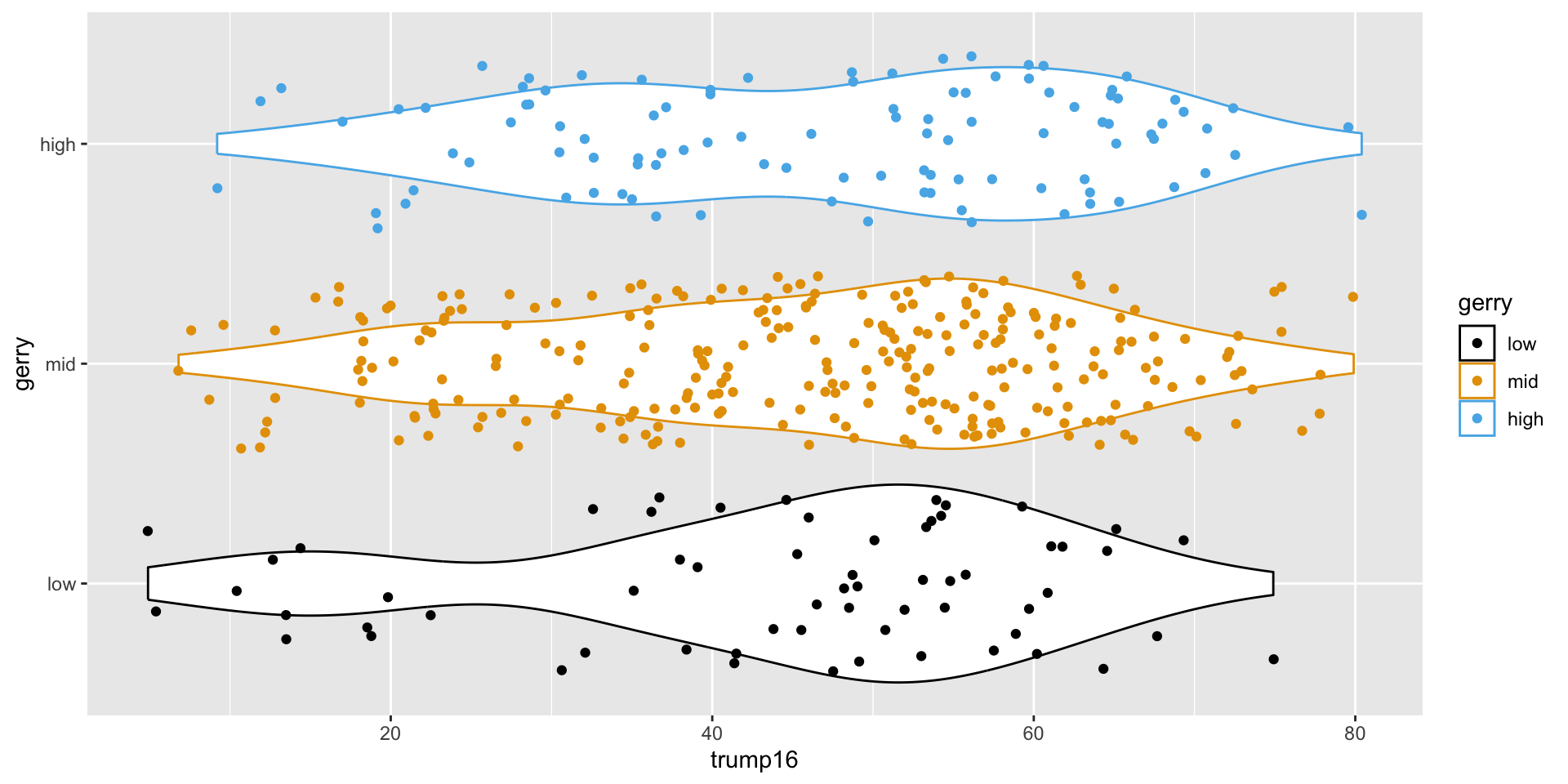
Remove legend