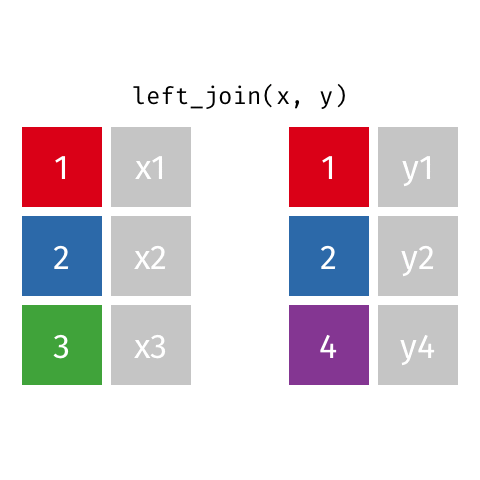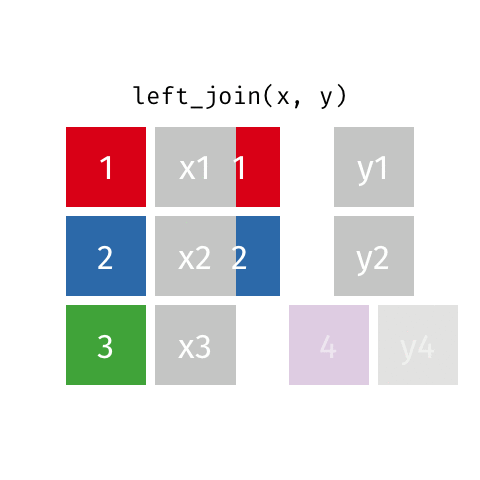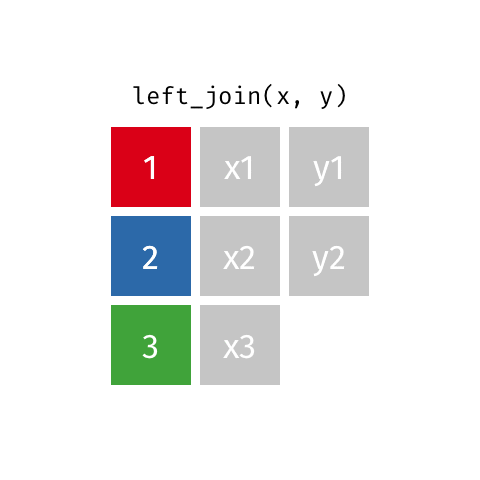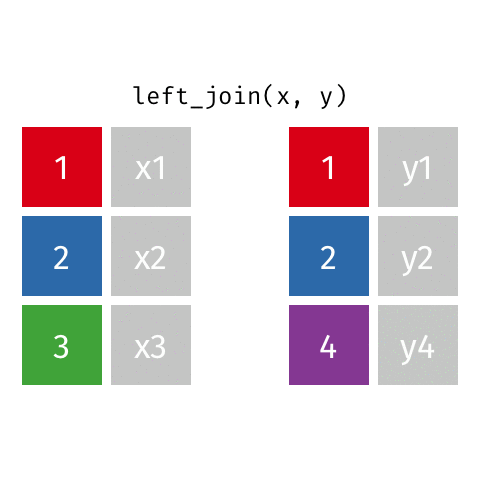
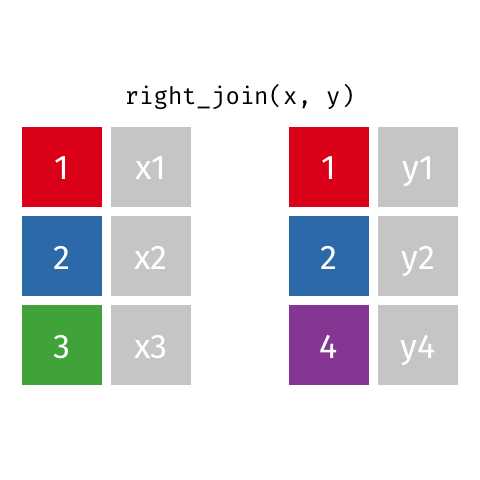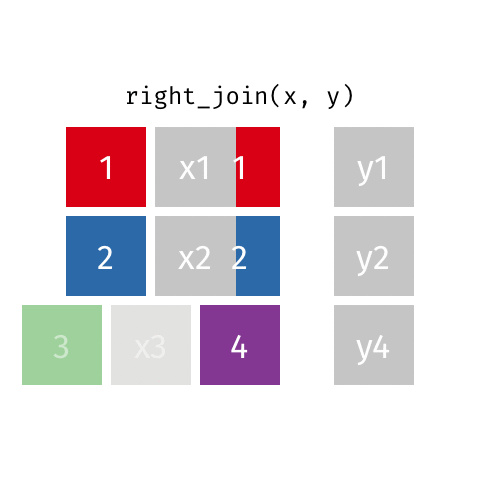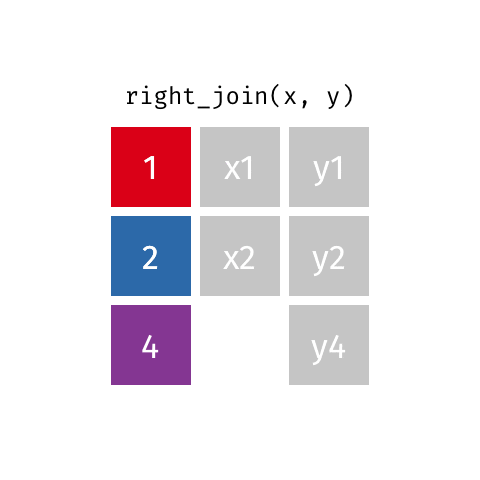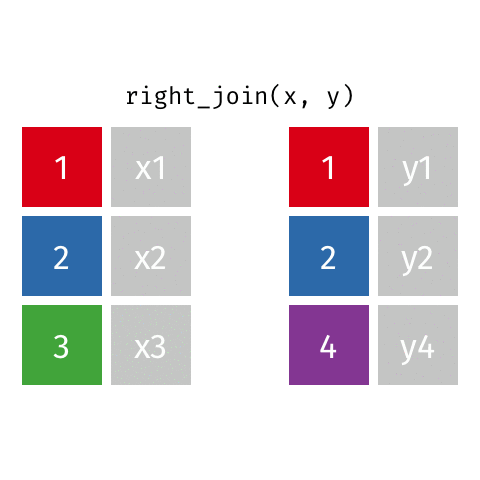
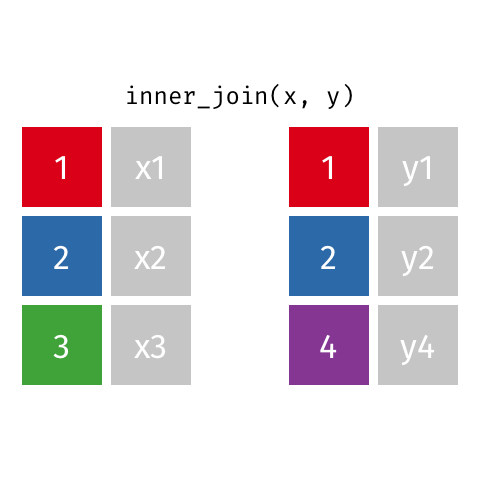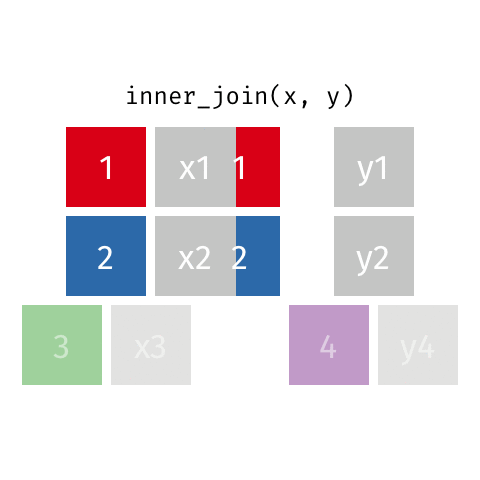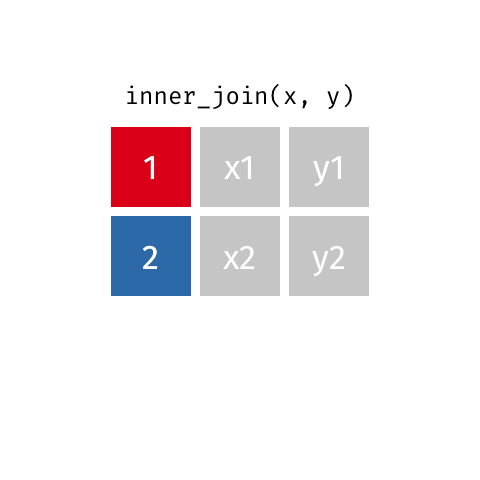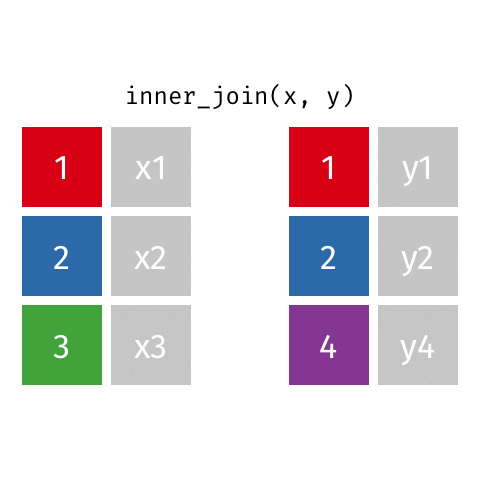
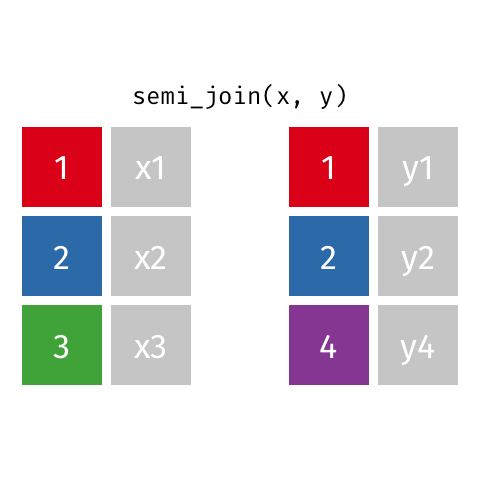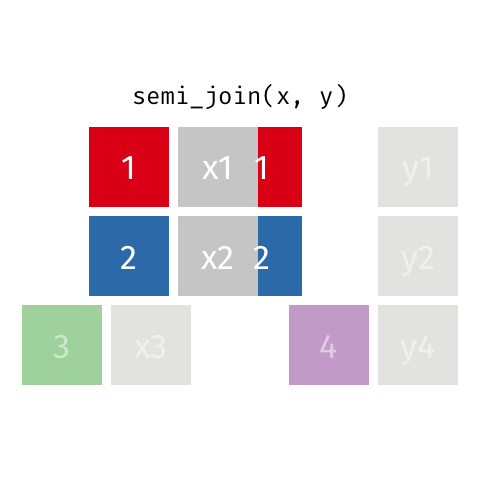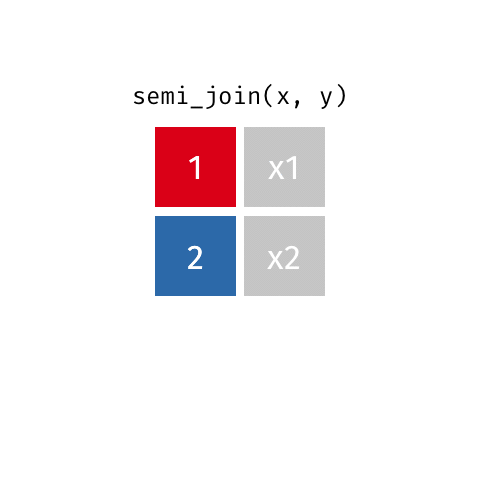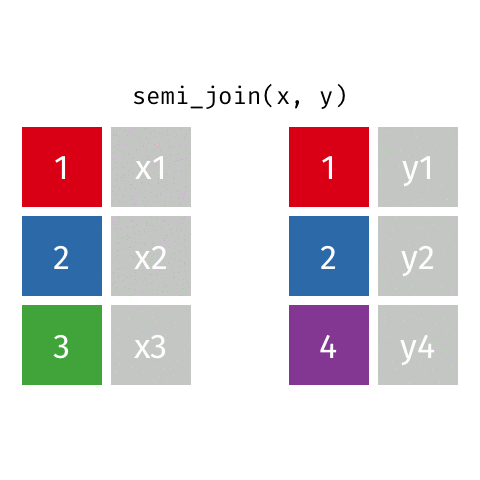
Joining data
Lecture 7
September 19, 2024
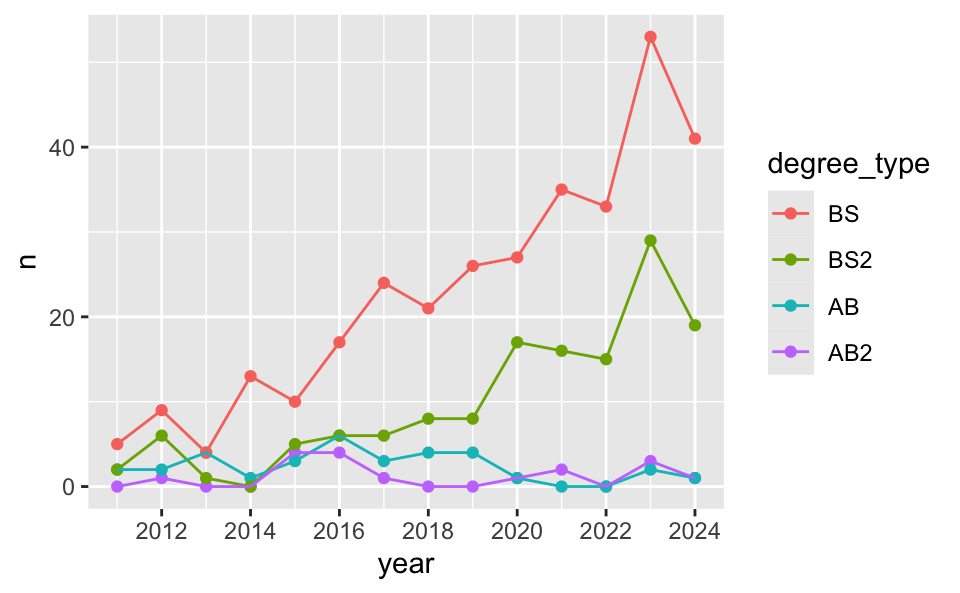
Recap: StatSci majors

Recap: Scales
Update x-axis scale: 2012 to 2024, increments of 2 years.
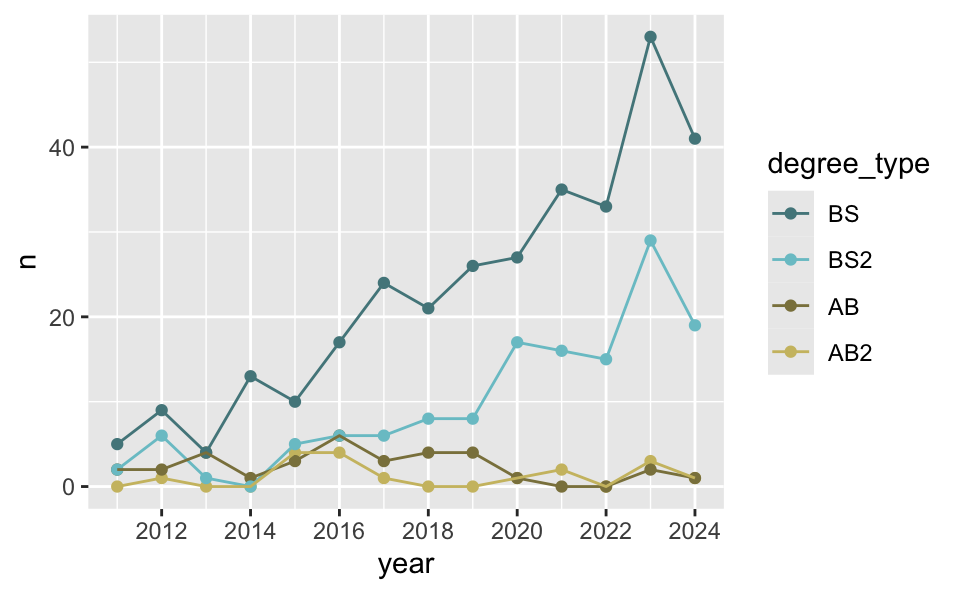
Recap: Colors
Use custom colors.
Recap: Labels and themes
Add custom labels and change theme.
ggplot(
statsci_longer,
aes(
x = year, y = n, color = degree_type
)
) +
geom_point() +
geom_line() +
scale_x_continuous(breaks = seq(2012, 2024, 2)) +
scale_color_manual(
values = c(
"BS" = "cadetblue4",
"BS2" = "cadetblue3",
"AB" = "lightgoldenrod4",
"AB2" = "lightgoldenrod3"
)
) +
labs(
x = "Graduation year",
y = "Number of majors graduating",
color = "Degree type",
title = "Statistical Science majors over the years",
subtitle = "Academic years 2011 - 2024",
caption = "Source: Office of the University Registrar\nhttps://registrar.duke.edu/registration/enrollment-statistics"
) +
theme_minimal()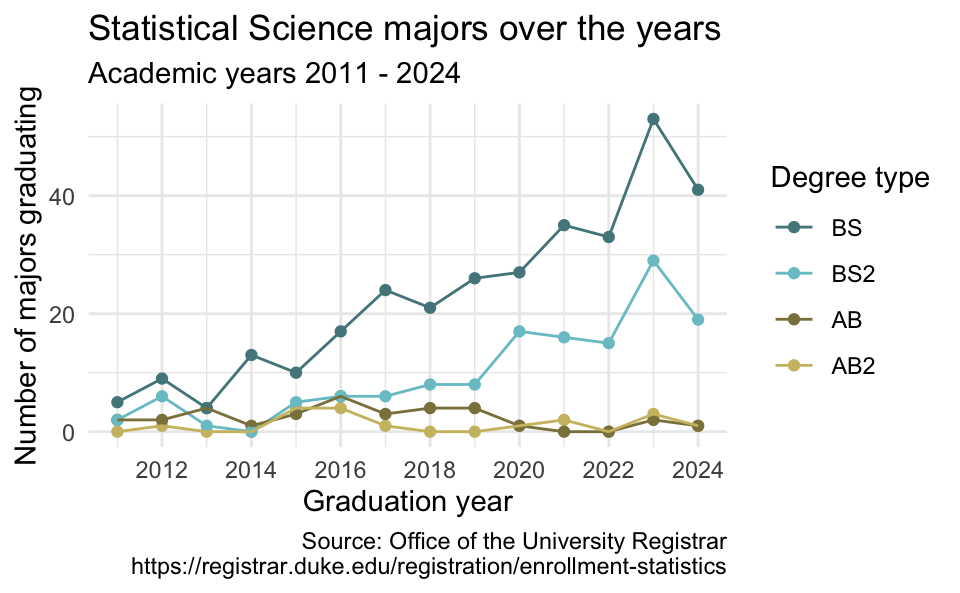
Recap: Legends
ggplot(
statsci_longer,
aes(
x = year, y = n, color = degree_type
)
) +
geom_point() +
geom_line() +
scale_x_continuous(breaks = seq(2012, 2024, 2)) +
scale_color_manual(
values = c(
"BS" = "cadetblue4",
"BS2" = "cadetblue3",
"AB" = "lightgoldenrod4",
"AB2" = "lightgoldenrod3"
)
) +
labs(
x = "Graduation year",
y = "Number of majors graduating",
color = "Degree type",
title = "Statistical Science majors over the years",
subtitle = "Academic years 2011 - 2024",
caption = "Source: Office of the University Registrar\nhttps://registrar.duke.edu/registration/enrollment-statistics"
) +
theme_minimal() +
theme(
legend.position = "inside",
legend.position.inside = c(0.1, 0.7),
legend.background = element_rect(fill = "white", color = "gray")
)
Recap: Plot sizing

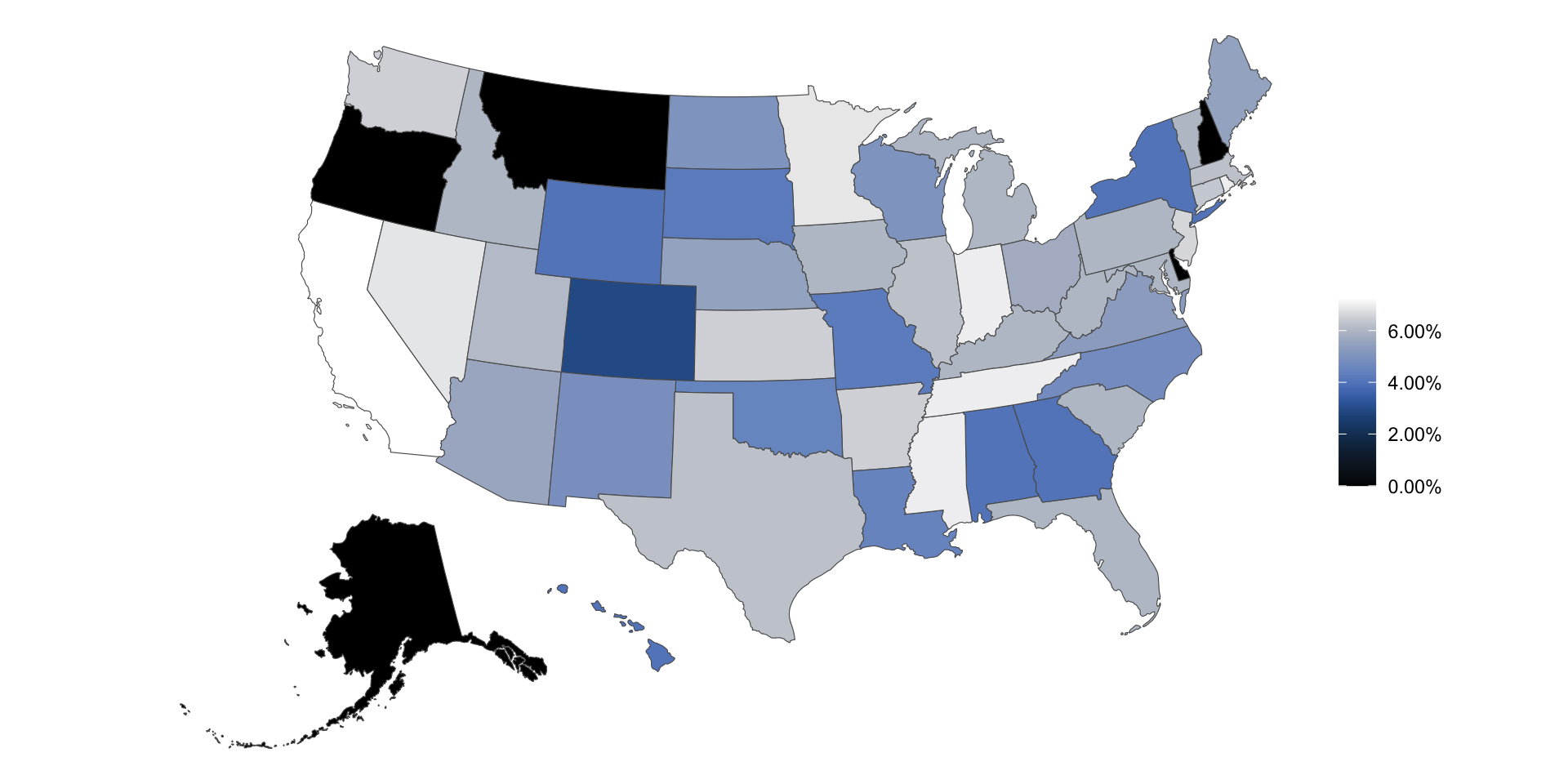
What’s going on in this plot?
Can you guess the variable plotted here?