Data science ethics
Lecture 13
October 17, 2024
Causality - TIME coverage
How plausible is the statement in the title of this article?

Causality - LA Times coverage
What does “research shows” mean?

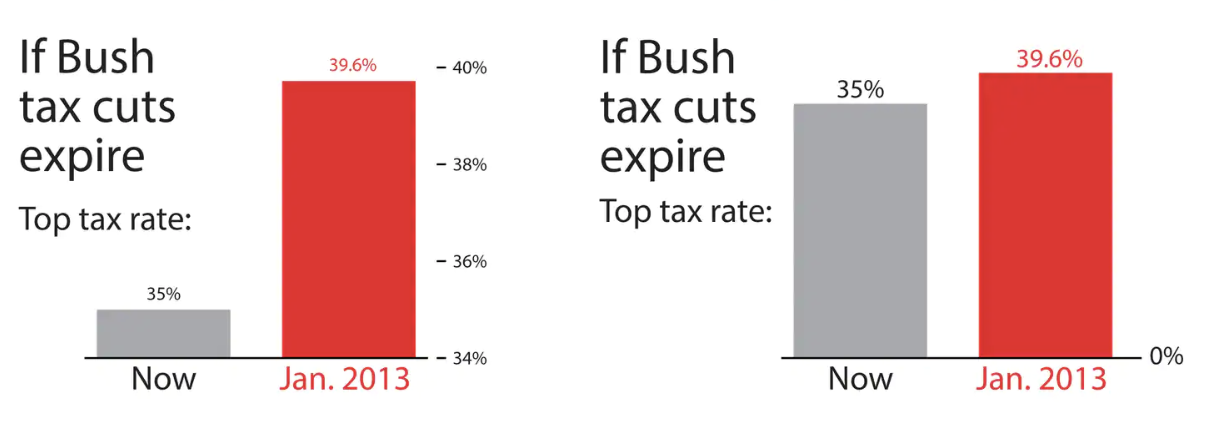
Axes and scales - Tax cuts
What is the difference between these two pictures? Which presents a better way to represent these data?
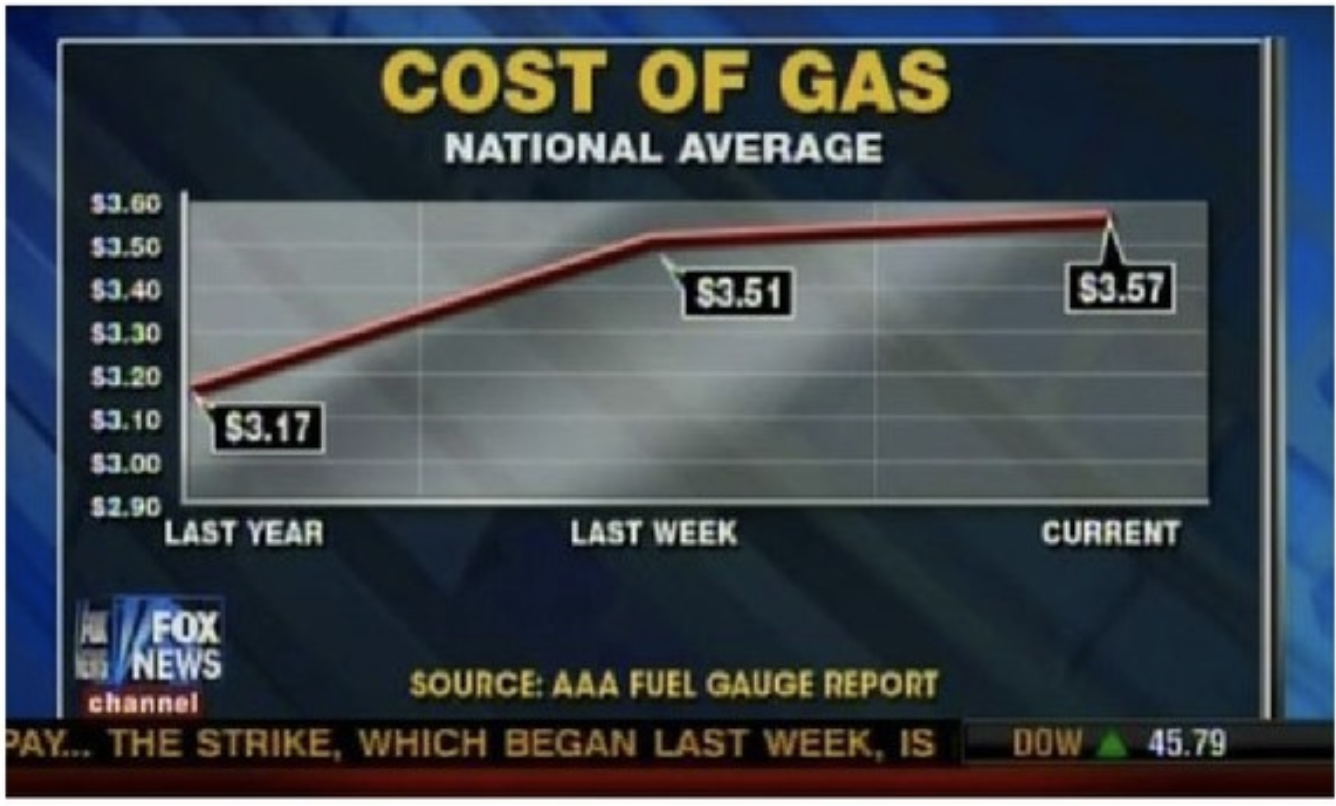
Axes and scales - Cost of gas
What is wrong with this picture? How would you correct it?
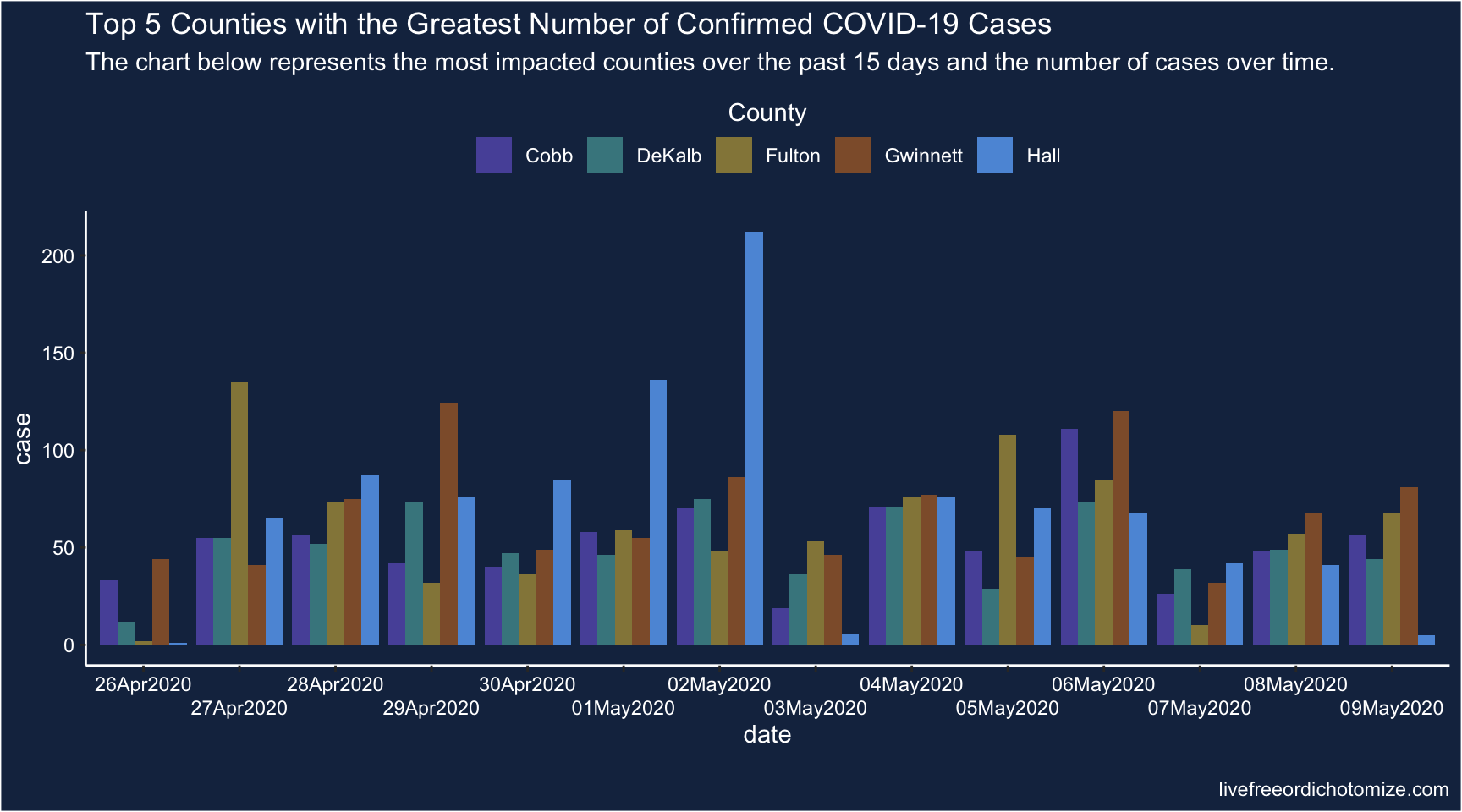
Axes and scales - COVID in GA
What is wrong with this picture? How would you correct it?

Axes and scales - COVID in GA
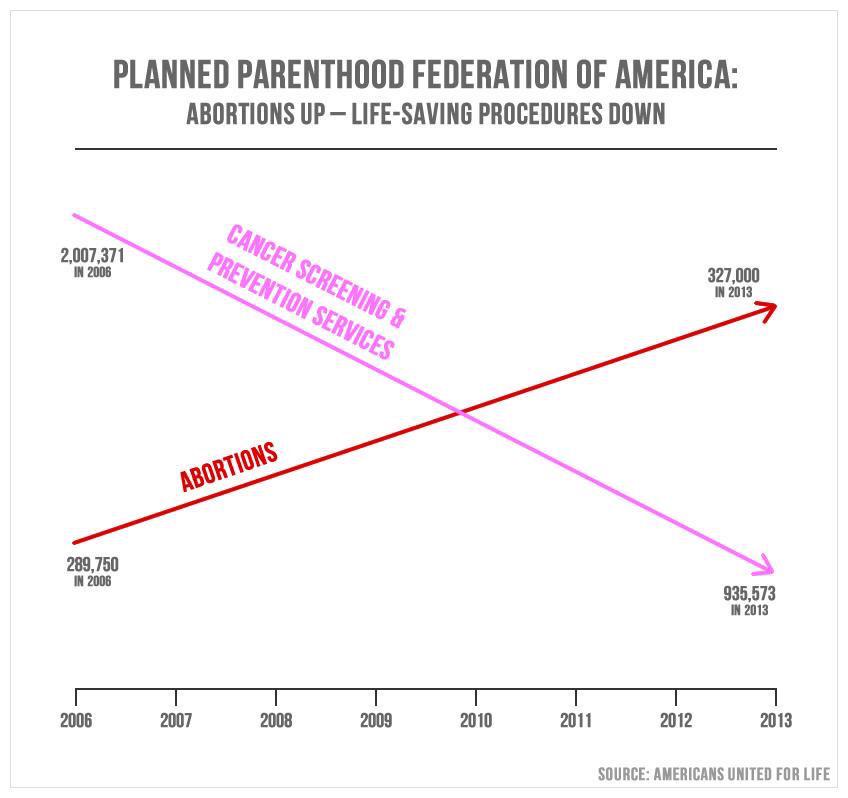
Axes and scales - PP services
What is wrong with this picture? How would you correct it?
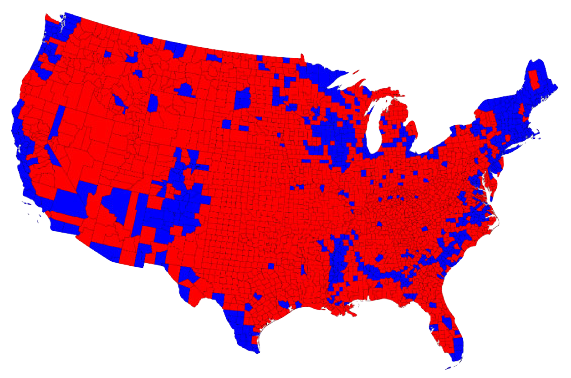
Maps and areas - Voting map
Do you recognize this map? What does it show?
Maps and areas - Two alternate tales


Maps and areas - Voting percentages
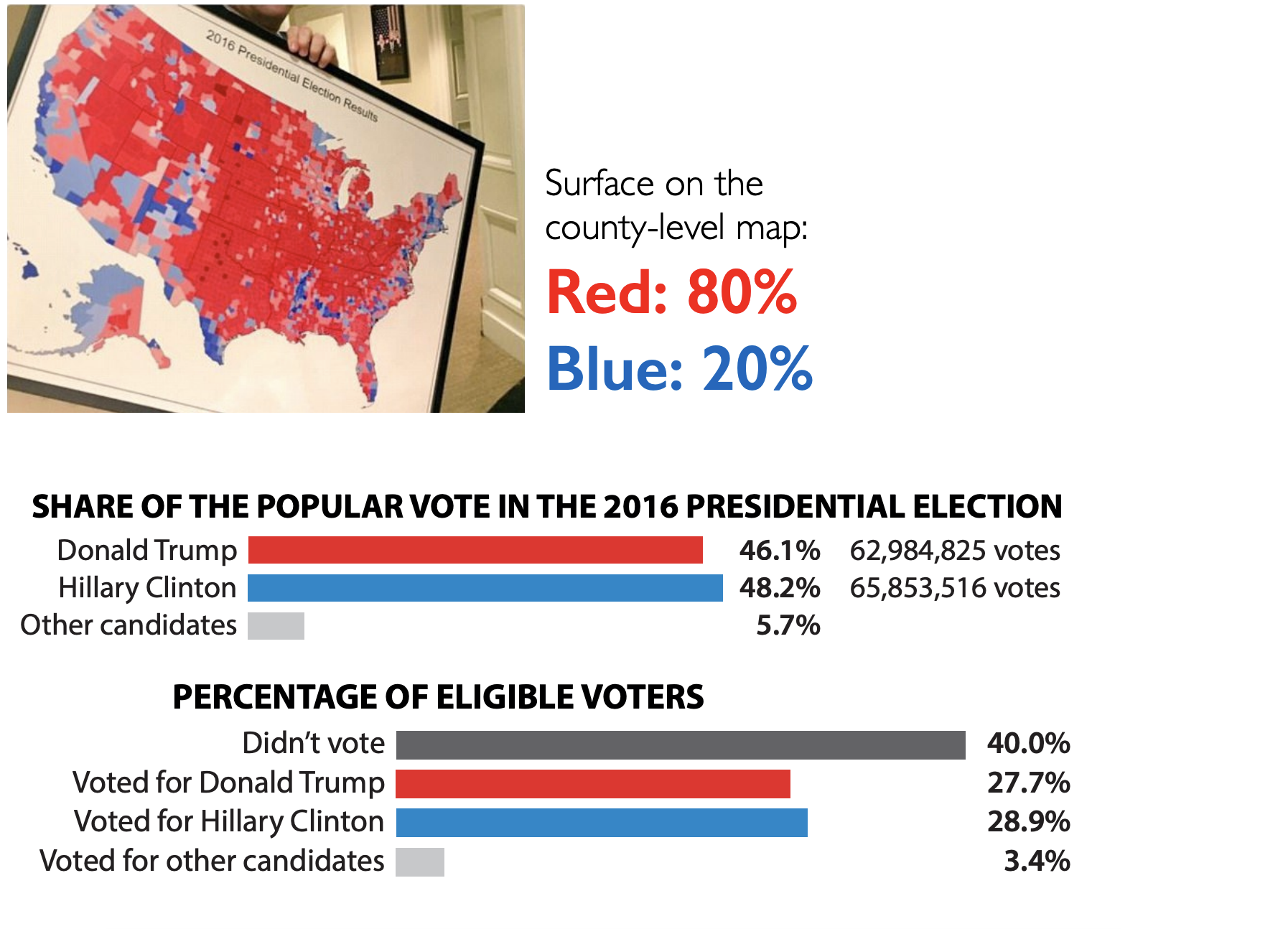
Maps and areas - Voting percentages

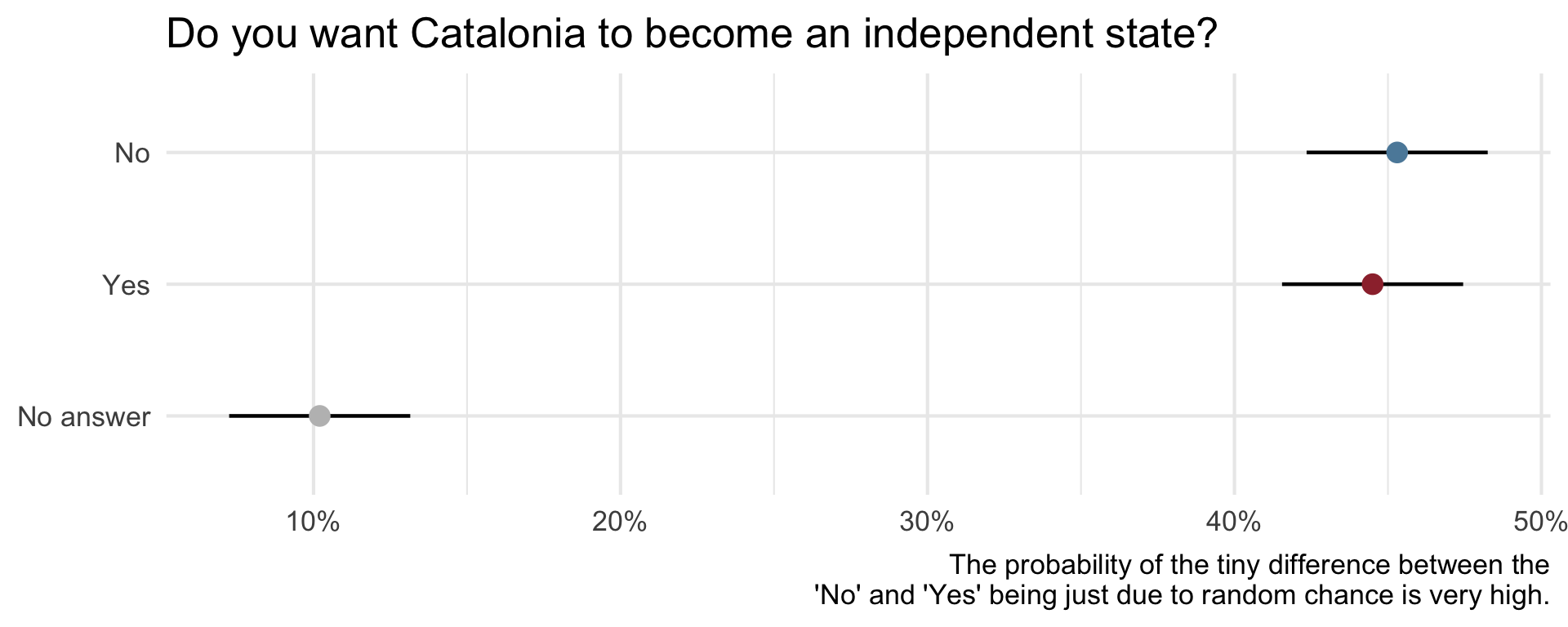
Uncertainty - Catalan independence
On December 19, 2014, the front page of Spanish national newspaper El País read “Catalan public opinion swings toward ‘no’ for independence, says survey”.
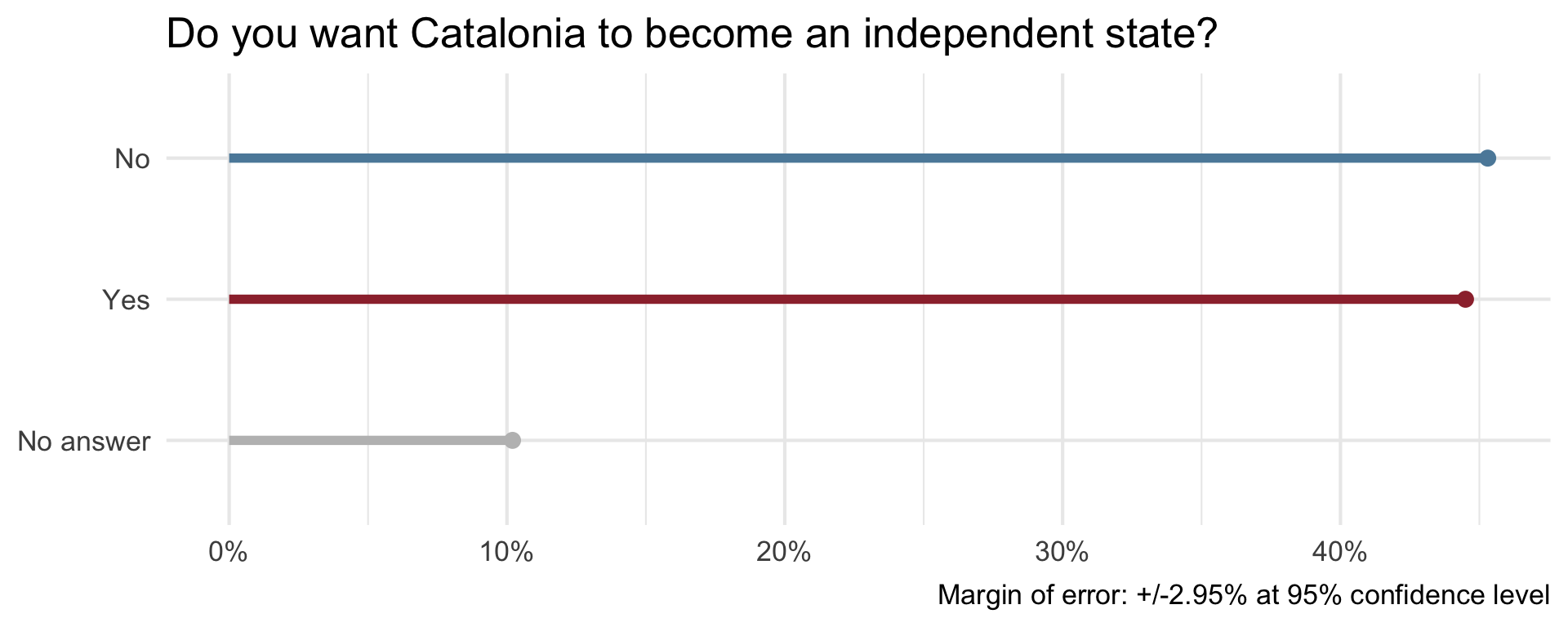
Uncertainty - Catalan independence
AOL search data leak

OK Cupid data breach

Google Translate
What might be the reason for Google’s gendered translation? How do ethics play into this situation?
![]()
Machine Bias
2016 ProPublica article on algorithm used for rating a defendant’s risk of future crime:
In forecasting who would re-offend, the algorithm made mistakes with black and white defendants at roughly the same rate but in very different ways.
The formula was particularly likely to falsely flag black defendants as future criminals, wrongly labeling them this way at almost twice the rate as white defendants.
White defendants were mislabeled as low risk more often than black defendants.

Risk score errors
What is common among the defendants who were assigned a high/low risk score for reoffending?


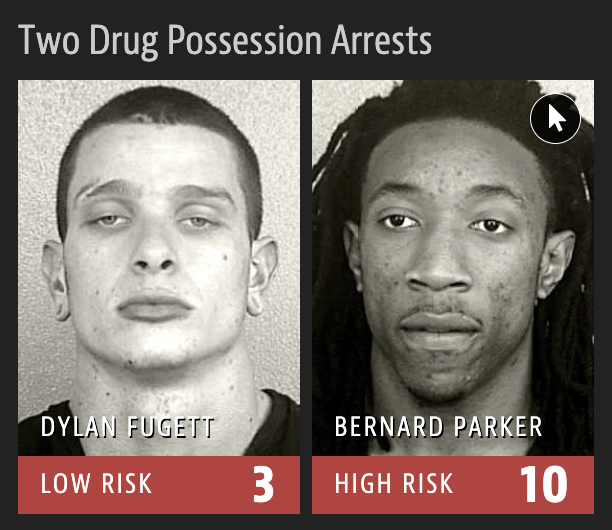

Risk scores
How can an algorithm that doesn’t use race as input data be racist?

How Charts Lie

Calling Bullshit

Calling Bullshit
The Art of Skepticism in a
Data-Driven World
by Carl Bergstrom and Jevin West
Machine Bias

by Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner
Ethics and Data Science

by Mike Loukides, Hilary Mason, DJ Patil
(Free Kindle download)
Weapons of Math Destruction

Weapons of Math Destruction
How Big Data Increases Inequality and Threatens Democracy
by Cathy O’Neil
Algorithms of Oppression

Algorithms of Oppression
How Search Engines Reinforce Racism
by Safiya Umoja Noble