AE 10: Opinion articles in The Chronicle
Suggested answers
Application exercise
Important
These are suggested answers. This document should be used as reference only, it’s not designed to be an exhaustive key.
Part 1 - Data scraping
See chronicle-scrape.R for suggested scraping code.
Part 2 - Data analysis
Let’s start by loading the packages we will need:
- Load the data you saved into the
datafolder and name itchronicle.
chronicle <- read_csv("data/chronicle.csv")- Who are the most prolific authors of the 500 most recent opinion articles in The Chronicle?
chronicle |>
count(author, sort = TRUE)# A tibble: 191 × 2
author n
<chr> <int>
1 Luke A. Powery 32
2 Advikaa Anand 26
3 Heidi Smith 26
4 Nik Narain 23
5 Monday Monday 20
6 Aaron Siegle 15
7 Anna Garziera 15
8 Sonia Green 12
9 Linda Cao 10
10 Angikar Ghosal 9
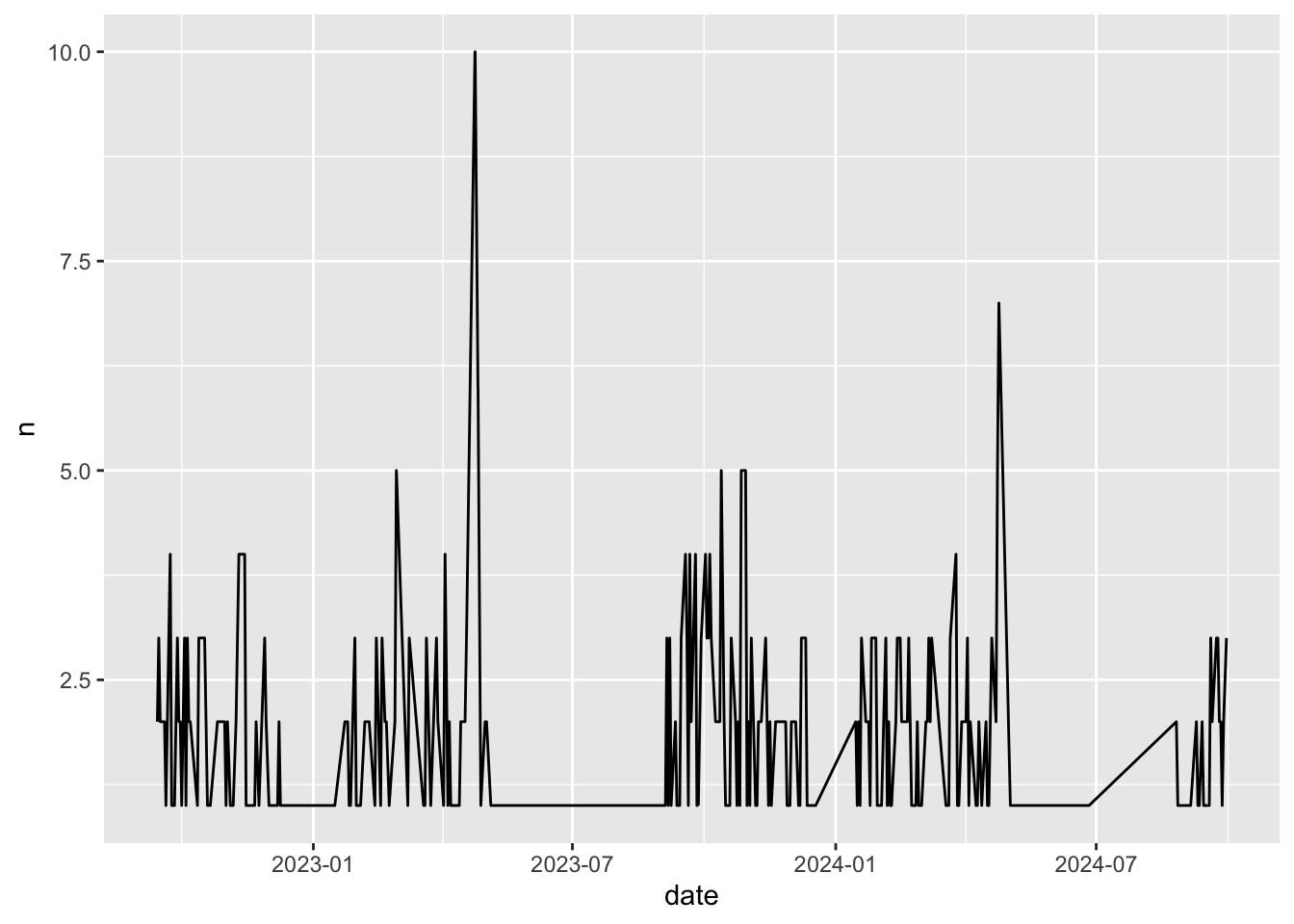
# ℹ 181 more rows- Draw a line plot of the number of opinion articles published per day in The Chronicle.
- What percent of the most recent 100 opinion articles in The Chronicle mention “climate” in their title?
chronicle |>
mutate(
title = str_to_lower(title),
climate = if_else(str_detect(title, "climate"), "mentioned", "not mentioned")
) |>
count(climate) |>
mutate(prop = n / sum(n))# A tibble: 2 × 3
climate n prop
<chr> <int> <dbl>
1 mentioned 11 0.022
2 not mentioned 489 0.978- What percent of the most recent 100 opinion articles in The Chronicle mention “climate” in their title or abstract?
chronicle |>
mutate(
title = str_to_lower(title),
abstract = str_to_lower(abstract),
climate = if_else(
str_detect(title, "climate") | str_detect(abstract, "climate"),
"mentioned",
"not mentioned"
)
) |>
count(climate) |>
mutate(prop = n / sum(n))# A tibble: 2 × 3
climate n prop
<chr> <int> <dbl>
1 mentioned 16 0.032
2 not mentioned 484 0.968- Come up with another question and try to answer it using the data.
# add code here